publications
2026
- Under Review
 Feedback World Model Enables Precise Guidance of Diffusion PolicyTuo An*, Jindou Jia*, Gen Li, Jingliang Li, Chuhao Zhou, and 6 more authorsarXiv preprint, 2026
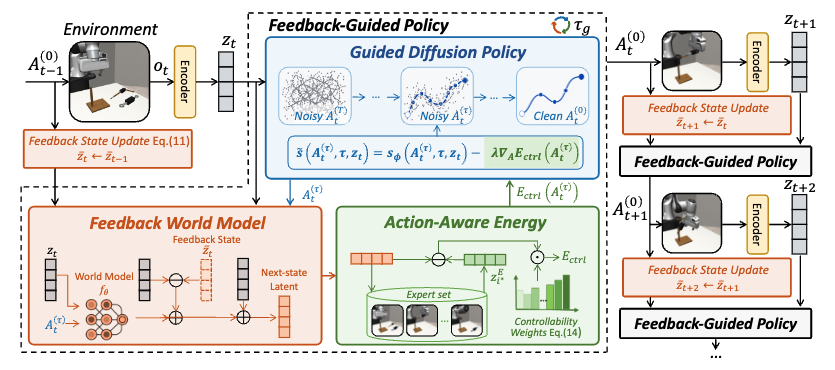
Feedback World Model Enables Precise Guidance of Diffusion PolicyTuo An*, Jindou Jia*, Gen Li, Jingliang Li, Chuhao Zhou, and 6 more authorsarXiv preprint, 2026World models aim to improve robotic decision making by predicting the consequences of actions. However, in practice, their predictions often become unreliable once the robot encounters states outside the training distribution, limiting their effectiveness at deployment. We observe that execution itself provides a natural but underutilized signal: after each action, the robot directly observes the true next state, revealing the mismatch between predicted and actual outcomes. Building on this insight, we propose feedback world model, a new paradigm that closes the loop between prediction and observation at inference time. Instead of treating the world model as a static open-loop predictor, our method maintains a lightweight feedback state that is updated online to iteratively correct future predictions, compensating for model errors using real-time observations without additional training data or parameter updates. We further introduce action-aware guidance to better translate corrected predictions into control by emphasizing action-controllable components while suppressing irrelevant variations. Experiments on LIBERO-Plus, Robomimic, and real-world manipulation tasks demonstrate that our method substantially improves both prediction accuracy and policy performance under distribution shift, reducing world model prediction error by up to 76.4% and improving out-of-distribution (OOD) success rate by 30%.
@article{an2026fwm, title = {Feedback World Model Enables Precise Guidance of Diffusion Policy}, author = {An, Tuo and Jia, Jindou and Li, Gen and Li, Jingliang and Zhou, Chuhao and Liu, Pengfei and Lyu, Bofan and Bai, Jiaqi and Guo, Xinying and Li, Geng and Yang, Jianfei}, journal = {arXiv preprint}, year = {2026}, } - Under Review
 MARS Policy: Multimodality Only When It MattersJindou Jia*, Tuo An*, Yuxuan Hu*, Gen Li, Jingliang Li, and 5 more authorsarXiv preprint, 2026
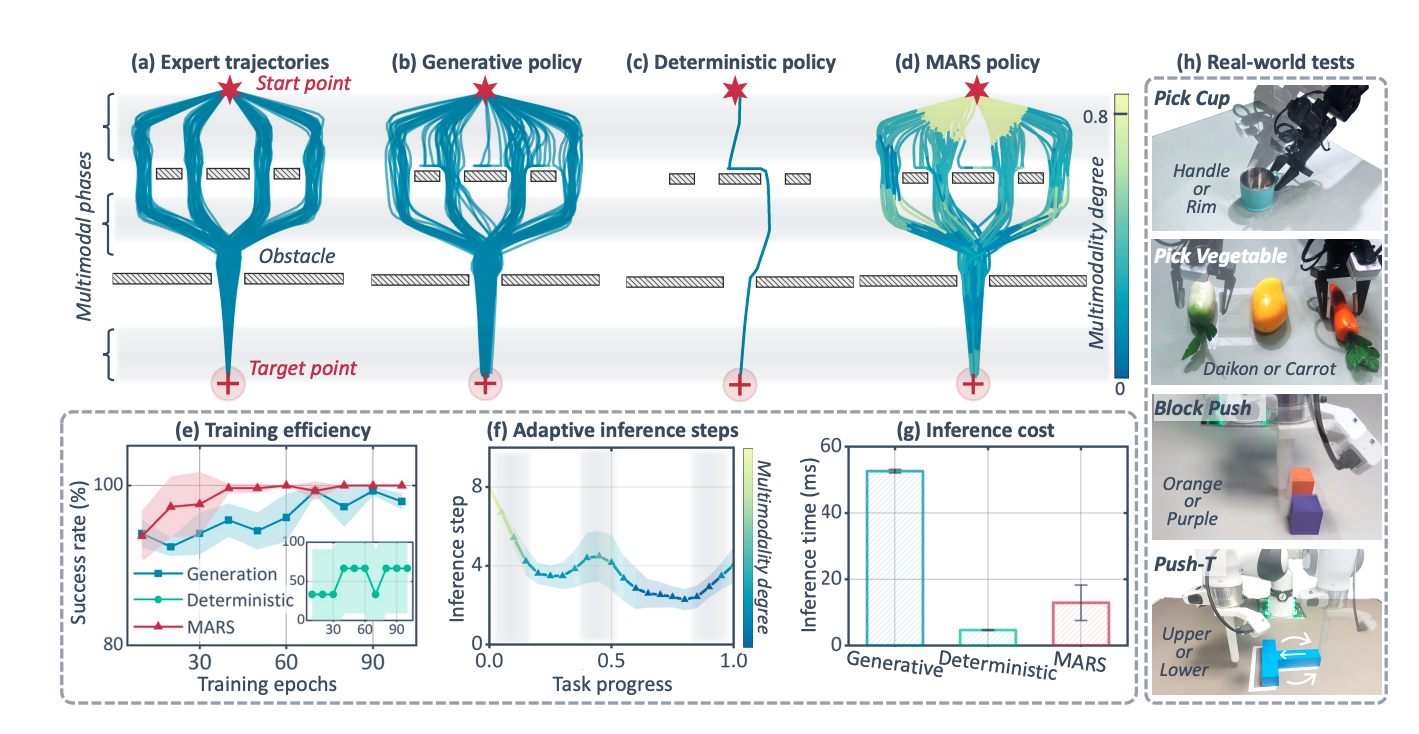
MARS Policy: Multimodality Only When It MattersJindou Jia*, Tuo An*, Yuxuan Hu*, Gen Li, Jingliang Li, and 5 more authorsarXiv preprint, 2026Imitation learning has become a cornerstone for solving complex robotic manipulation tasks. In particular, multimodality, which enables robots to capture diverse yet valid behavioral patterns, has driven the rapid emergence of generative policies as a dominant paradigm in robot learning. However, achieving such multimodality typically relies on stochastic noise initialization and iterative denoising procedures, resulting in substantial training complexity and low inference efficiency. Meanwhile, not all phases of a robotic task inherently require behavioral diversity. Motivated by this insight, we propose the Modality-Adaptive Robot Sampling (MARS) policy, which adaptively invokes tailored stochasticity only when it is truly beneficial, while reverting to an efficient deterministic learning during single-modal phases. By selectively activating multimodal generation, MARS policy bridges the gap between the multimodal capability of generative policies and the superior training and inference efficiency of deterministic models. Empirical studies across 8 simulated and 4 real-world tasks demonstrate that MARS exhibits robust multimodal expressivity and high efficiency, with a 16.67% success rate improvement and an 83.20% inference latency reduction in real-world tests.
@article{jia2026marspolicy, title = {MARS Policy: Multimodality Only When It Matters}, author = {Jia, Jindou and An, Tuo and Hu, Yuxuan and Li, Gen and Li, Jingliang and Hou, Bohan and Chen, Xiangyu and Bai, Jiaqi and Lyu, Bofan and Yang, Jianfei}, journal = {arXiv preprint}, year = {2026}, } - RSS
 Action-to-Action Flow MatchingJindou Jia, Gen Li, Xiangyu Chen, Tuo An, Yuxuan Hu, and 3 more authorsIn Proceedings of Robotics: Science and Systems (RSS), 2026
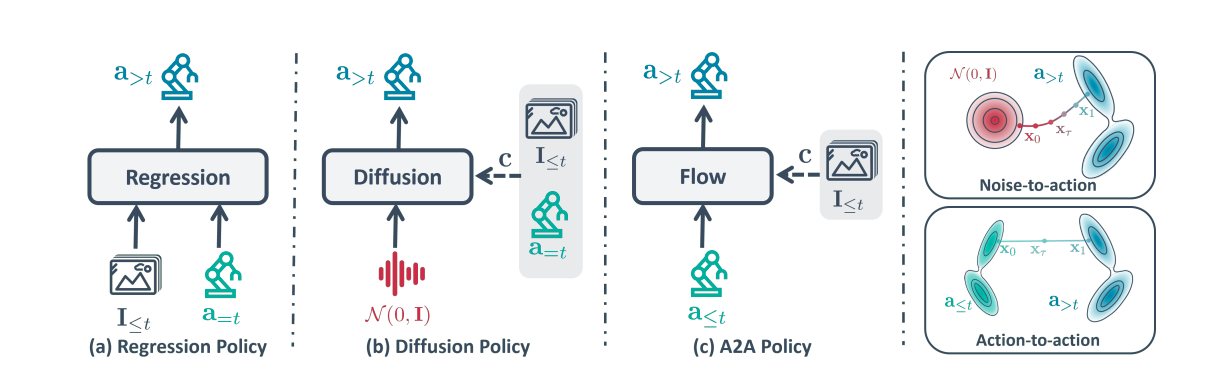
Action-to-Action Flow MatchingJindou Jia, Gen Li, Xiangyu Chen, Tuo An, Yuxuan Hu, and 3 more authorsIn Proceedings of Robotics: Science and Systems (RSS), 2026We introduce Action-to-Action Flow Matching (A2A), a policy-learning framework that frames imitation learning as a flow-matching problem directly in action space, mapping past actions to future actions conditioned on observations. Compared with regression-based and diffusion-based policies, A2A delivers more efficient sampling and stronger generalization in robot manipulation.
@inproceedings{jia2026a2a, title = {Action-to-Action Flow Matching}, author = {Jia, Jindou and Li, Gen and Chen, Xiangyu and An, Tuo and Hu, Yuxuan and Li, Jingliang and Guo, Xinying and Yang, Jianfei}, booktitle = {Proceedings of Robotics: Science and Systems (RSS)}, year = {2026}, } - Survey
 World Model for Robot Learning: A Comprehensive SurveyBohan Hou*, Gen Li*, Jindou Jia*, Tuo An*, Xinying Guo*, and 13 more authorsarXiv preprint, 2026
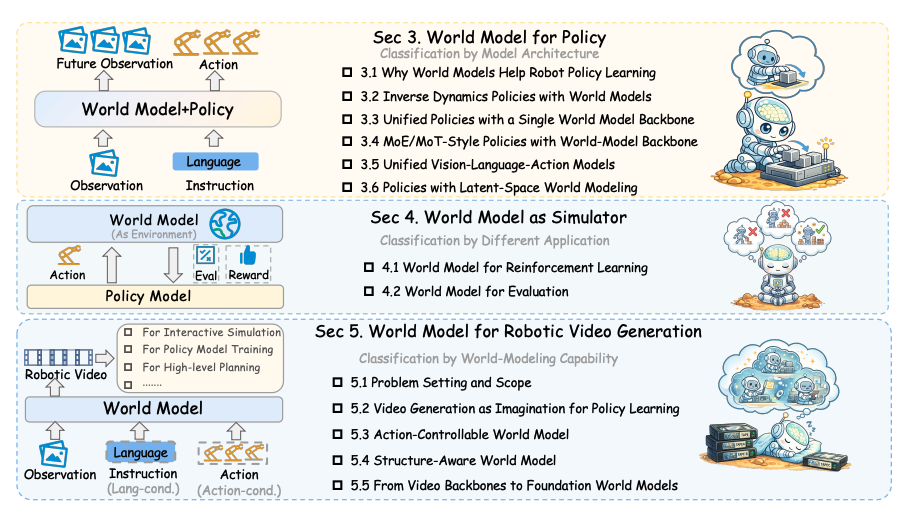
World Model for Robot Learning: A Comprehensive SurveyBohan Hou*, Gen Li*, Jindou Jia*, Tuo An*, Xinying Guo*, and 13 more authorsarXiv preprint, 2026A comprehensive survey on world models for robot learning. We organize the literature along three axes: world models that augment policies, world models that serve as simulators for reinforcement learning and evaluation, and world models for robotic video generation. We summarize recent progress, identify open challenges, and outline a roadmap toward foundation world models for embodied AI.
@article{hou2026worldmodel, title = {World Model for Robot Learning: A Comprehensive Survey}, author = {Hou, Bohan and Li, Gen and Jia, Jindou and An, Tuo and Guo, Xinying and Leng, Sicong and Geng, Haoran and Ze, Yanjie and Harada, Tatsuya and Torr, Philip and Mees, Oier and Pollefeys, Marc and Liu, Zhuang and Wu, Jiajun and Abbeel, Pieter and Malik, Jitendra and Du, Yilun and Yang, Jianfei}, journal = {arXiv preprint}, year = {2026}, } - Under Review
 CompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing ObjectsJingliang Li, Jindou Jia, Tuo An, Chuhao Zhou, Xiangyu Chen, and 5 more authorsarXiv preprint, 2026
CompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing ObjectsJingliang Li, Jindou Jia, Tuo An, Chuhao Zhou, Xiangyu Chen, and 5 more authorsarXiv preprint, 2026We present CompassAD, an intent-driven 3D affordance grounding benchmark and method that targets functionally competing objects. The dataset comprises 88K QA pairs over 6.4K scenes across 105 object categories with 30 confusing pairs, and we validate the approach with real-world robotic deployment.
@article{li2026compassad, title = {CompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing Objects}, author = {Li, Jingliang and Jia, Jindou and An, Tuo and Zhou, Chuhao and Chen, Xiangyu and Shan, Shilin and Ma, Boyu and Lyu, Bofan and Li, Gen and Yang, Jianfei}, journal = {arXiv preprint}, year = {2026}, }
2025
- Under Review
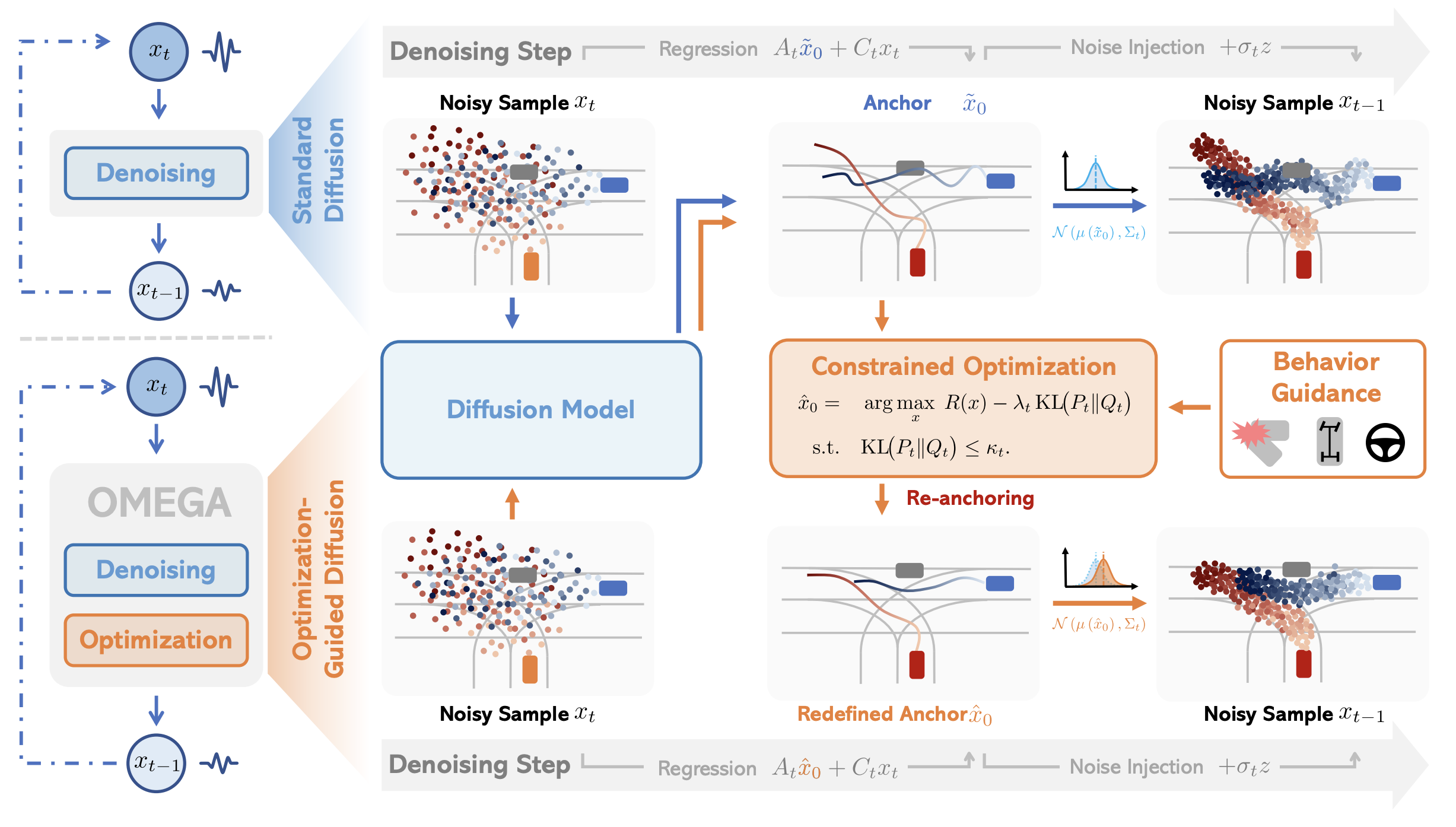 Optimization-Guided Diffusion for Interactive Scene GenerationShihao Li, Naisheng Ye, Tianyu Li, Kashyap Chitta, Tuo An, and 5 more authorsIn arXiv preprint, 2025
Optimization-Guided Diffusion for Interactive Scene GenerationShihao Li, Naisheng Ye, Tianyu Li, Kashyap Chitta, Tuo An, and 5 more authorsIn arXiv preprint, 2025Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability.
@inproceedings{li2025optimization, title = {Optimization-Guided Diffusion for Interactive Scene Generation}, author = {Li, Shihao and Ye, Naisheng and Li, Tianyu and Chitta, Kashyap and An, Tuo and Su, Peng and Wang, Boyang and Liu, Haiou and Lv, Chen and Li, Hongyang}, booktitle = {arXiv preprint}, year = {2025}, } - Cell Press
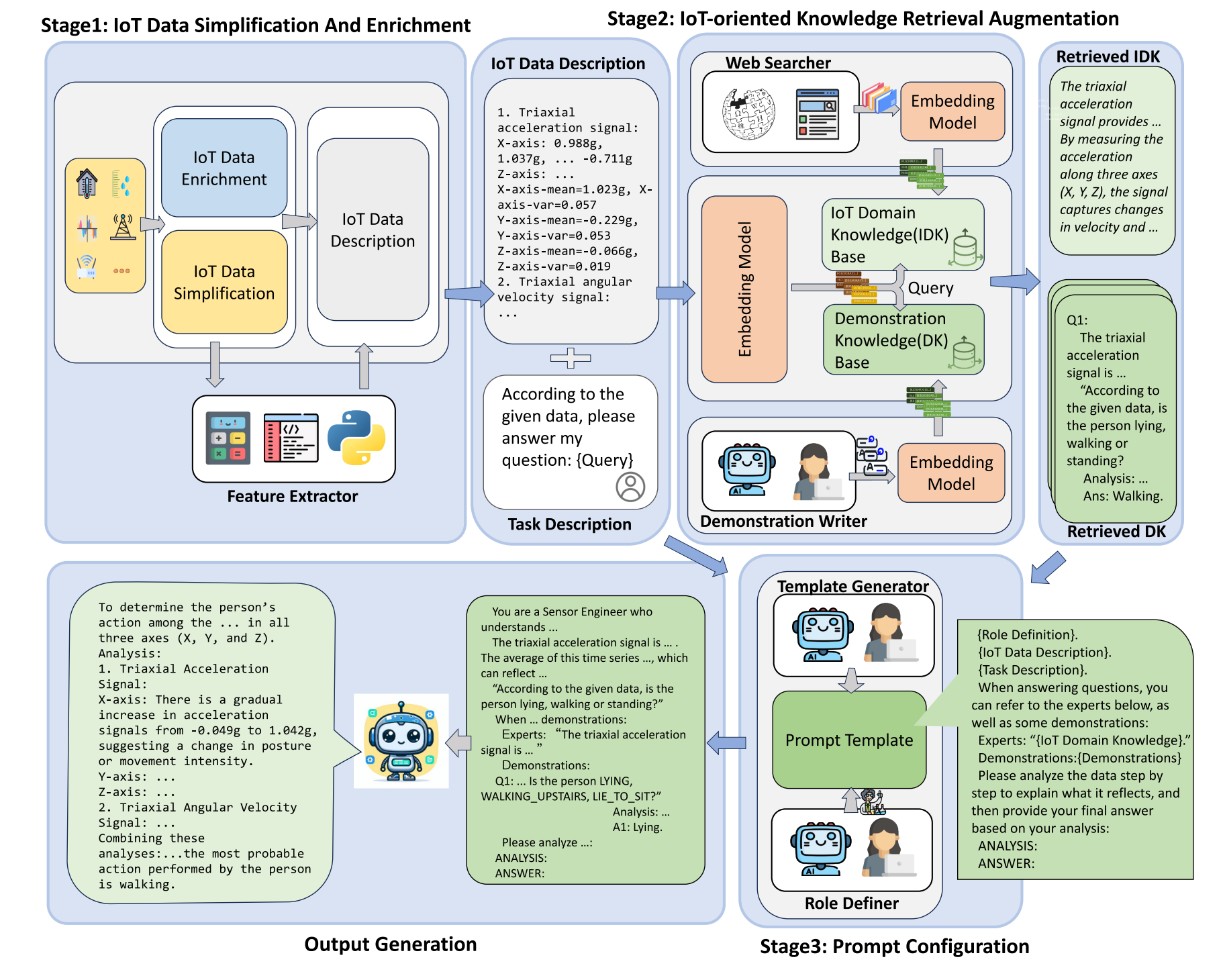 Iot-llm: Enhancing real-world iot task reasoning with large language modelsTuo An, Yunjiao Zhou, Han Zou, and Jianfei YangPatterns, Cell Press (Cover Paper), 2025
Iot-llm: Enhancing real-world iot task reasoning with large language modelsTuo An, Yunjiao Zhou, Han Zou, and Jianfei YangPatterns, Cell Press (Cover Paper), 2025This paper presents a novel approach to enhancing real-world IoT task reasoning with large language models. We demonstrate significant improvements in performance across various benchmarks.
@article{an2024iot, title = {Iot-llm: Enhancing real-world iot task reasoning with large language models}, author = {An, Tuo and Zhou, Yunjiao and Zou, Han and Yang, Jianfei}, journal = {Patterns, Cell Press (Cover Paper)}, year = {2025}, }
2024
- EMNLP
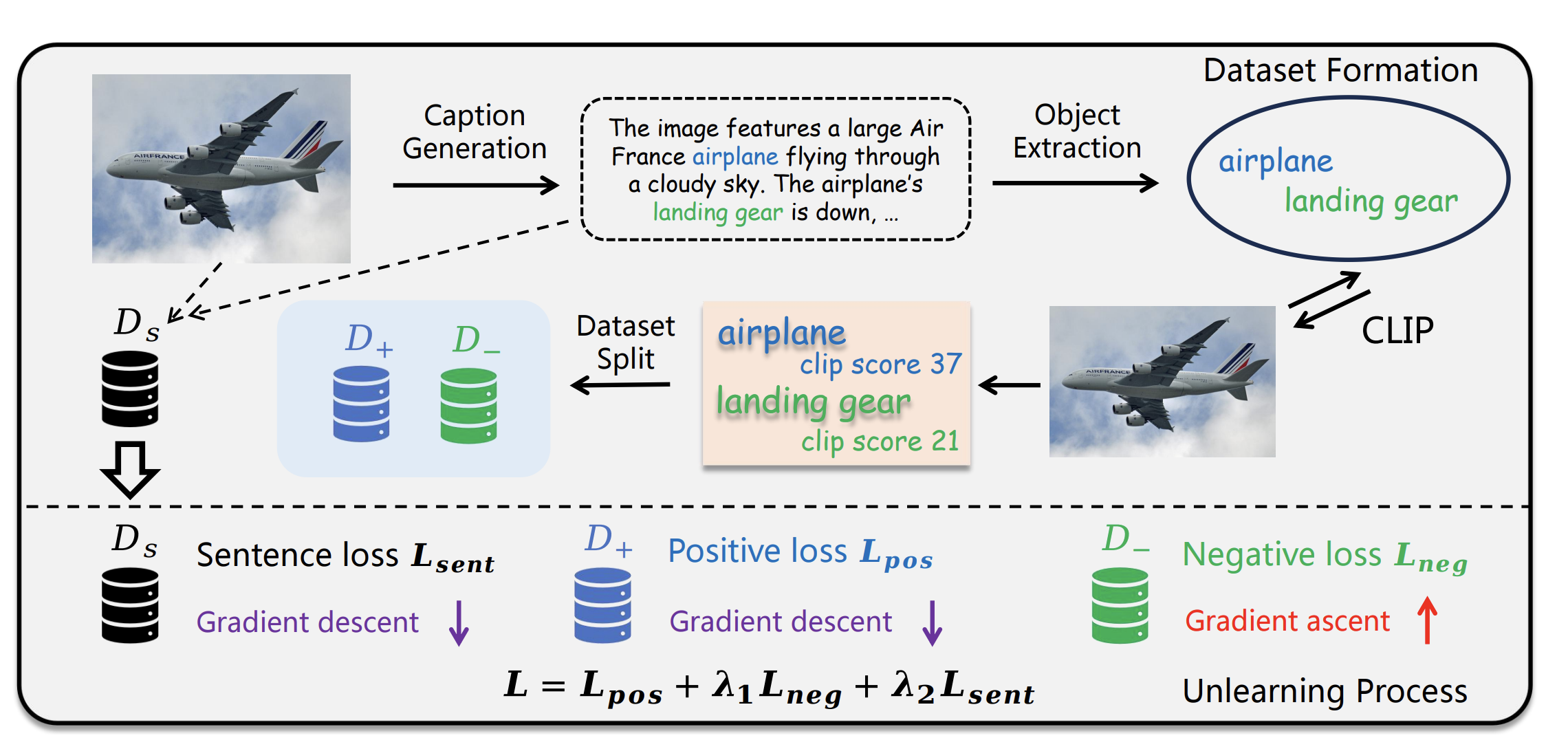 EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language ModelsShangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, and 3 more authorsIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language ModelsShangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, and 3 more authorsIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, we propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead.
@inproceedings{xing2024efuf, title = {EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models}, author = {Xing, Shangyu and Zhao, Fei and Wu, Zhen and An, Tuo and Chen, Weihao and Li, Chunhui and Zhang, Jianbing and Dai, Xinyu}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, year = {2024}, }